ZAICOでは、Android・iOS・Rubyエンジニアを絶賛募集中です! 詳しくは、採用ページをご覧ください。

はじめに
こんにちは! ZAICO開発チームです。
突然ですが、テーブル設計における隣接リストパターンをご存知でしょうか?
近頃、DynamoDBを利用する機会が増えたので、この隣接リストパターンについて、(ほぼ自分のために)まとめておこうと思います。
さて、DynamoDB(NoSQL)の設計手法について、AWSの公式ドキュメントには以下のような一文がありました(過去形:現在はもう少し緩めの言い回しになってます)
DynamoDB アプリケーションではできるだけ少ないテーブルを維持する必要があります。設計が優れたアプリケーションでは、必要なテーブルは 1 つのみです。
この一文を目にした当時、完全にRDBMS脳だった私は、しばらくの間、混乱状態だったのを覚えています。
え?そんなこと・・・ほんとにできるの・・?
といった具合です。
やってみると、本当に出来るのですが、このとき利用する考え方が「隣接リスト」という設計パターンになります。
具体的にどういった設計ができるのか、例を挙げて考えてみたいと思います。
とある在庫管理システム
かなり簡略化していますが、ユーザーが商品を登録して、その在庫数や保管場所を管理できるシステムを例にテーブル設計をしてみました。
(変更履歴にも対応!)
↓ テーブル設計の例
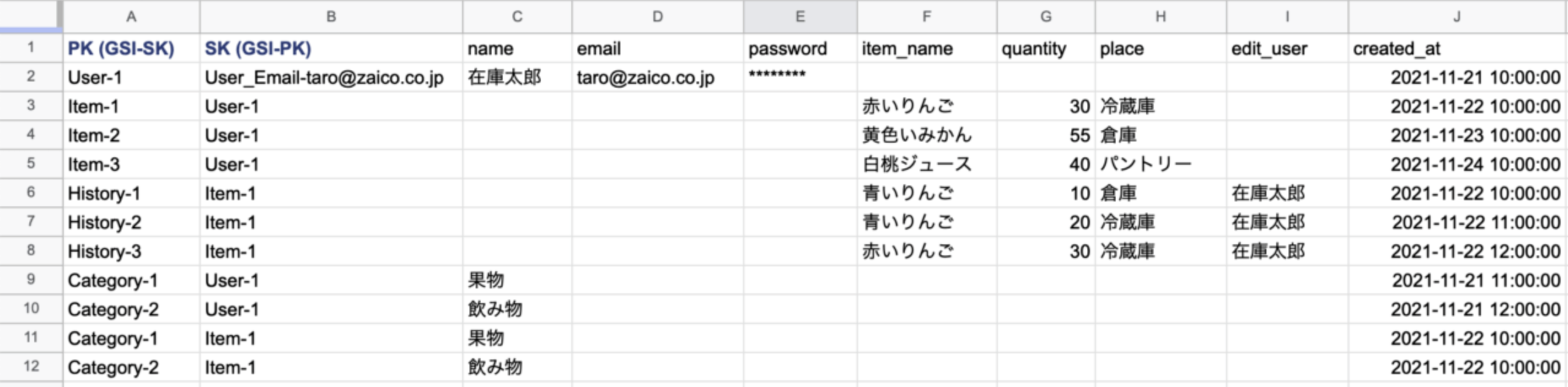
それぞれ、各行ごとに説明していきます。
先頭行
先頭行はテーブルの各属性(カラム)になります。
といっても重要なのは、PK (GSI-SK), SK (GSI-PK) だけで、それ以外はただの属性です。
PKはパーティションキーで、SKはソートキーと呼ばれる特殊な意味を持つカラムになります。
DynamoDBではクエリを発行する際、PKを必ず指定する必要があります。
SKについては任意ですが、並べ替えに利用したり、前方一致でデータをさらに絞り込んだりできるので、こちらも重要なカラムです。
さて、PKとSKを使えばある程度はデータ抽出ができそうですが、隣接リストパターンを実現するには不十分です。
例えば、上の例のようなデータ構造だと、「ユーザー(User-1)が管理している商品一覧を取得する」という、普通に出来そうなことが実は出来ません。
もちろん、PKとSKの値を入れ替えて格納しておけば出来るのですが、今度は逆に「商品(Item-1)の詳細情報を取得する」という、これまた普通に出来そうなことが出来なくなります。
グローバルセカンダリインデックス(GSI)
そこで、グローバルセカンダリインデックス(GSI)という仕組みを導入することで、この問題を解決します。
(グローバルセカンダリインデックスについては、こちらをご参照ください)
今回はSKに対してGSIのPKを、PKに対してはGSIのSKを逆張りするイメージでしょうか。
こうすることで、PK,SKに対して、双方向にクエリを発行することができるようになります。
PK,SKの値について
PK,SKに対しては(今回だとItem-1やUser-1のような)ユニークなキー文字列を発行することが多くなると思います。
(これはパーティションに偏りが生じないようにするためにも有効。 参考:パーティションとデータ分散)
最も簡単な実装として、uuid等のユニークな文字列を使うのが楽だと思いますが、加えて、timestampも含めておくことをオススメします。
例えば、「Item-(timestamp)-(uuid)」のような生成ルールにしておくことで、クエリ発行時に並べ替え項目(ソートキー)として使えるので便利です。
なお、DynamoDBではPK,SK以外のカラムに対してクエリを発行することは基本的にできませんので注意が必要です。
もちろんフィルター(クエリ結果に対して絞り込むこと)は可能ですが、パフォーマンス的な観点から、むやみに使用すべきではないでしょう。
この場合、データ構造を工夫したり、必要に応じて、OpenSearch等の他のサービスと組み合わせることを検討すべきだと思います。
さて、すでに大切な点は書いてしまったので、あとは簡単に各行を眺めていきます。
2行目
ユーザー情報です。
SK (GSI-PK)にはメールアドレスを含ませているので、ログイン処理時の逆引きに利用できそうです。
3-5行目
商品情報です。
SK (GSI-PK)を利用してクエリを発行すれば、User-1が管理している商品情報を一覧取得することができそうですし、
逆に、PK (GSI-SK)を利用すれば、商品詳細ページなどでデータを引っ張ることも容易いでしょう。
6-8行目
変更履歴です。
Item-1に対して「いつ」「誰が」「どのように」変更したのかが、ログとして残されています。
これなら商品ごとの履歴一覧・詳細画面等で、うまくデータを引っ張れそうです。
9-10行目
カテゴリマスタです。
ユーザーが登録したカテゴリを一覧で取得、とか簡単にできそうです。
11-12行目
商品とカテゴリとの紐付け情報です。
一つの商品に対して、複数のカテゴリが紐づく一般的なデータ構造かと思います。
nameカラムにはカテゴリ名を冗長化して持たせてますので、例えば商品詳細ページ等でカテゴリ情報を表示する際は、最小限のクエリで情報を引っ張ることができそうです。
ただし、カテゴリマスタ更新時には非同期処理等で、冗長化された側のデータも書き換える必要があるでしょう。
ちなみに、nameカラムはユーザー情報でも利用しているので最初は不思議かもしれませんが、DynamoDB(NoSQL)では特に問題にはなりません(もちろん、category_nameのように分けて格納してもいい)
以上です。
まとめ
今回はDynamoDB(NoSQL)の設計手法の一つ隣接リストパターンについて書いてみました。
以下、自分なりのまとめです。
- PK (GSI-SK), SK (GSI-PK)の組み合わせがユニークであれば、データの入れ方は基本的に自由(ただし、パーティションが偏らないように各キー発行ルールは工夫する)
- PK,SKにはtimestampを仕込んでおくと何かと便利(昇順・降順で並び替えしたくなることがあるので)
- スプレッドシート1枚で表現できているか、書き出してみるといい(正規化したくなったら負け)
- 取り出しやすい(クエリで検索しやすい)形でデータが格納されているか、を意識する(必要なら冗長化も厭わない)
- DynamoDB(NoSQL)だけで全てを実現しようとしない(特に検索はOpenSearch等の他サービス利用も検討する)
検索まわりだけなんとかできれば、個人的には十分に実用的だと考えてます。